|
"All models are wrong, but some are useful." – George Box [Name pronounced either as Saw-rv or Show-oo-rob in Bengali] I am a fourth-year Ph.D. student in Computer Science at the University of Colorado Boulder, where I am advised by Prof. Lijun Chen. My research lies at the intersection of theoretical machine learning and online learning, with a focus on algorithms for sequential decision-making under uncertainty. My research focuses on the mathematical foundations of online learning and sequential decision-making, particularly in uncertain or evolving environments. I study problems where feedback is partial or delayed, and where learning must adapt to structural constraints such as network topology, temporal drift, or incentive compatibility. Prior to my Ph.D., I completed a Master’s in Computer Science at the University of Colorado Boulder. I earned my bachelor's degree from the Birla Institute of Technology, Mesra in Ranchi, India, and worked as a software engineer at Flipkart in Bangalore before moving to the U.S. Beyond research, I find myself drawn to cinema, literature, and music. I keep an archive of films I've watched here, and a list of books here. Lately, I’ve also begun sharing fragments of music and poetry here. I’ve also carried with me, since childhood, a quiet devotion to cricket. I played for a local club during school, then for the Flipkart team, and now I follow the game as an ever-watchful spectator. Although I no longer play, the game continues to ground me, a thread back to childhood and to the quieter parts of myself that persist beneath everything else. |

Taken in Ouray, Colorado, |
|
|
|
I work on theoretical machine learning, with a focus on online learning and sequential decision-making under uncertainty. My research studies how structural constraints, such as limited feedback, local movement, and evolving graph structure, shape the learnability of an environment. I design algorithms that are provably efficient, even in settings where actions are constrained and global information is unavailable. This agenda has led to contributions in incentivized exploration, where agents are compensated to overcome myopic behavior under non-stationary rewards, and in graph-constrained bandits, where local movement and dynamic connectivity dictate exploration and learning. My current work develops methods for learning on structured and random graphs, designing algorithms that adapt gracefully to feedback, movement, and temporal drift. *Equal Contribution |
|
Sourav Chakraborty*, Amit Kiran Rege*, Claire Monteleoni, Lijun Chen Accepted at IEEE Conference on Decision and Control (CDC) 2025 in Rio de Janeiro, Brazil. IEEE version (yet to come) / arXiv
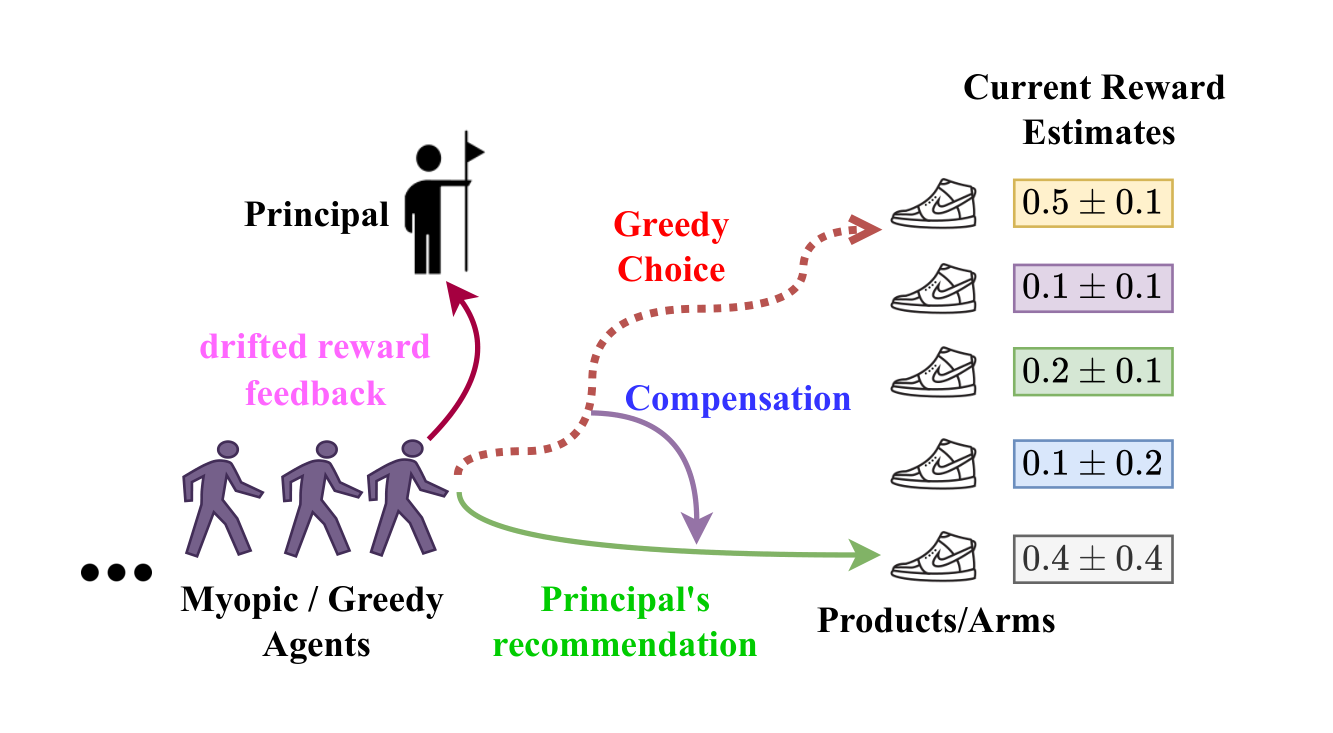
We study incentivized exploration in bandit settings with infinitely many arms over continuous metric spaces. A principal offers compensation to myopic agents to encourage exploration, but must contend with reward drift due to biased feedback.
We develop discretization-based algorithms that achieve both sublinear regret and sublinear compensation, with guarantees of \( \widetilde{O}(T^{(d+1/d+2)}) \) where \( d \) is the covering dimension. We extend our approach to contextual bandits and validate it through simulations.
|
|
Sourav Chakraborty and Lijun Chen. Accepted at IEEE American Control Conference (ACC) 2024 in Toronto, Canada. Master's Thesis, Committee: Lijun Chen, Raf Frongillo, Bo Waggoner. IEEE version / arXiv / thesis
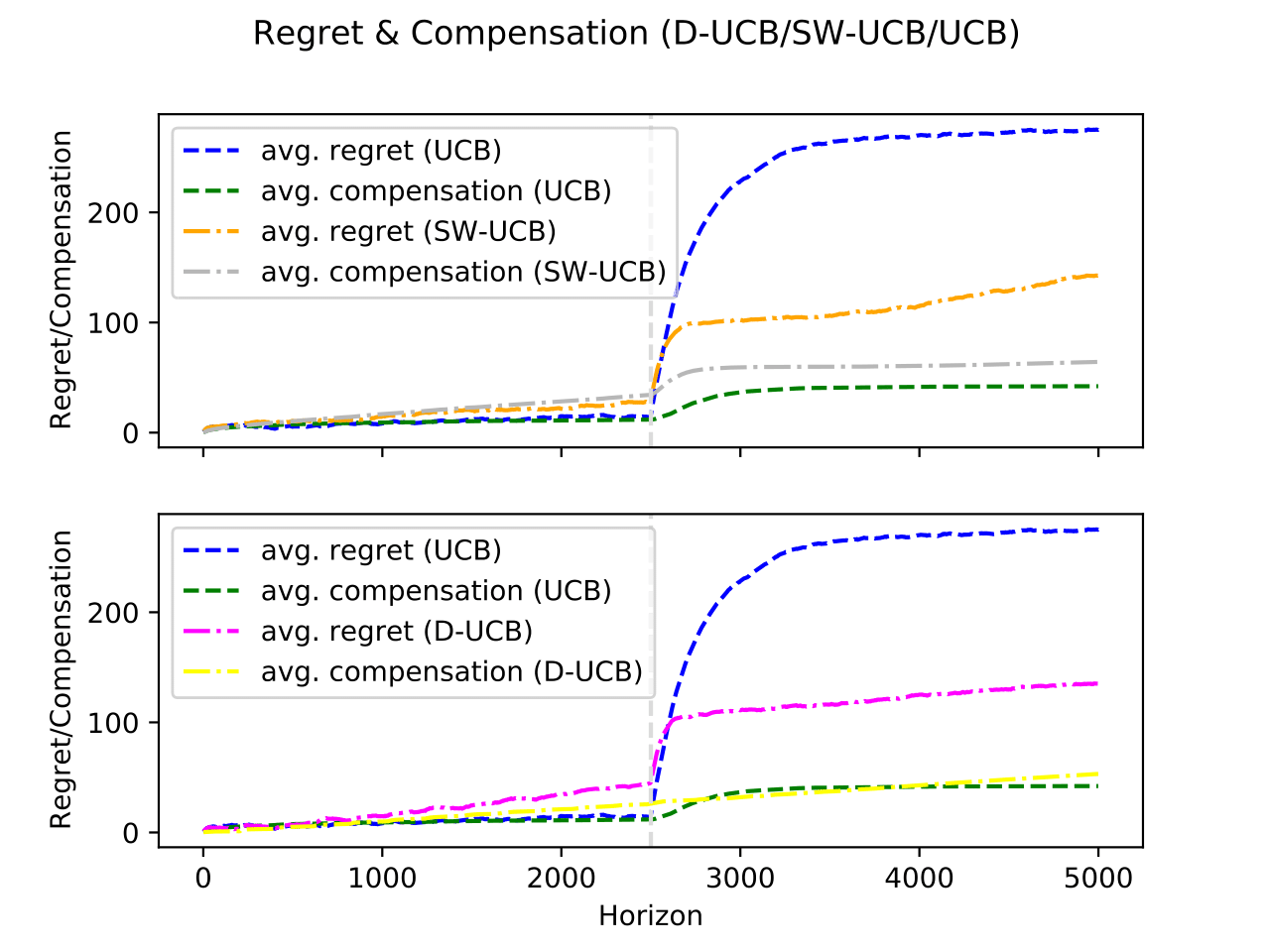
We study incentivized exploration in non-stationary bandit settings, where agents receive compensation to explore beyond their greedy choices, but report biased feedback.
We propose algorithms for both abruptly-changing and continuously-drifting environments, and show they achieve sublinear regret and compensation, even under biased rewards, thus enabling effective exploration over time.
|
|
|
|
|
*Alphabetically |
|
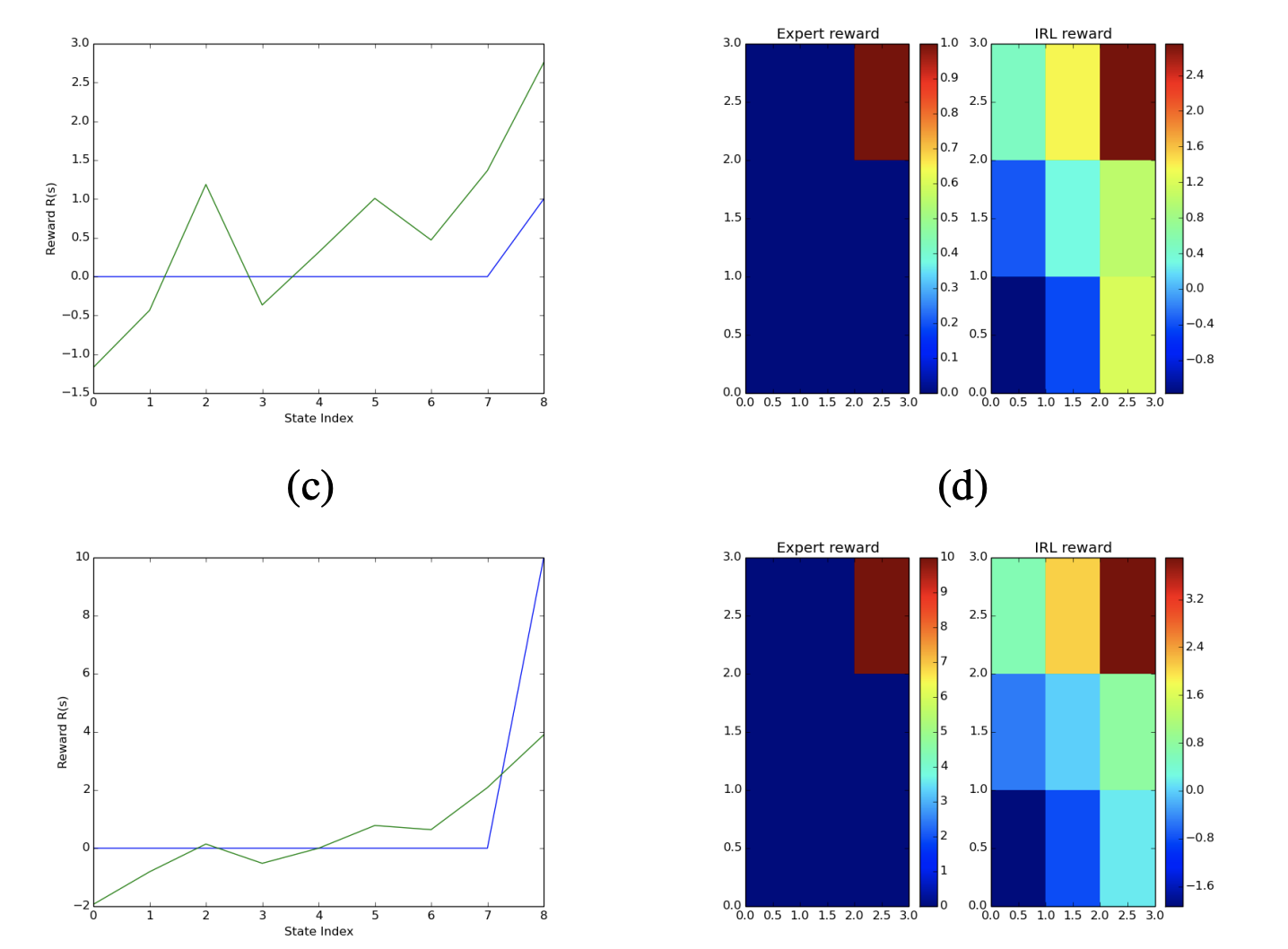
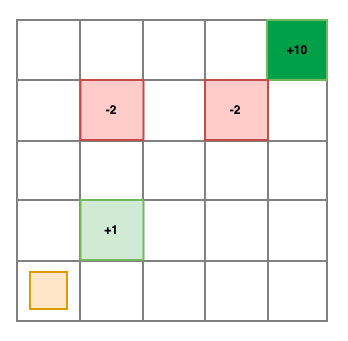
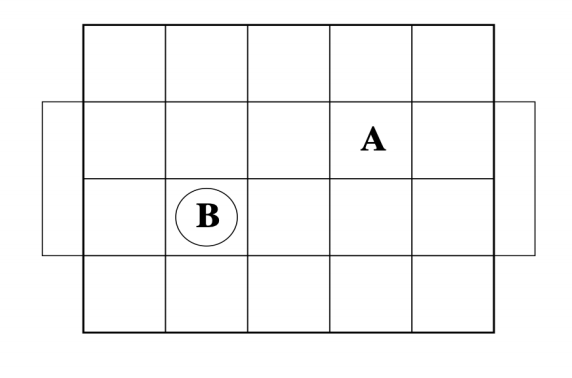
Tuhina Tripathi, Alexa Reed, Sourav Chakraborty April , 2022 report / code / demo / interface-code Final project for ASEN 5519: Decision Making Under Uncertainty. This project explores the use of Inverse Reinforcement Learning, via Maximum Entropy Formulation, in a Markov Decision Process. The concepts explored in this project were demonstrated using a grid world environment. |
|
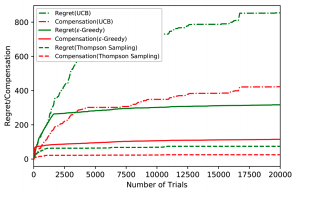
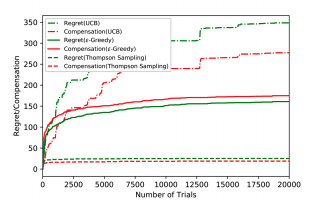
Sourav Chakraborty September, 2020 original paper / code Just playing around with the paper by Liu & Wang et alon Incentivized Exploration for Multi-Armed Bandits under Reward Drift where the players receive compensation for exploring arms other than the greedy choice and may provide biased feedback on reward drift. |
|
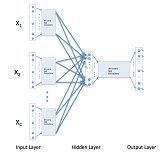
*Amit Baran Roy, Sourav Chakraborty May, 2020 report / code A word embedding model implementation based on the popular skipgram architecture. It involves alterations of the scoring algorithm to give more weightage to the context words that are closer to the target word in a skipgram sliding window. |
|
Sourav Chakraborty, Nagarajan Shanmuganathan May, 2020 report / code It is known well that Counterfactual regret minimization (CFR) has been used in games which have both terminal states and perfect recall to minimize regret. This project aims to relax those constraints and use a local no-regret algorithm (LONR) by Kash et al, which internally uses a Q-learning like update rule to games which do not have terminal states or perfect recall. |
|
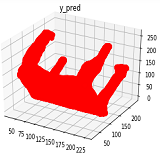
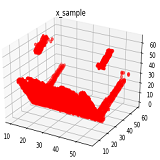
*Amit Baran Roy, Aparajita Singh, Sourav Chakraborty, Tanmai Gajula Feb-April, 2020 report / code The complete 3D geometry of an object from a single 2.5D depth view was acquired by using deep learning techniques such as generative adversarial networks and 3D convolution neural networks. The resolution of the final 3D voxelized output was improved by transforming the voxel representation into another representation called occupancy networks. |
Last updated: Aug 2025
Thanks Jon Barron!